
A bounded in-memory cache for async operations written in F#
I am currently working on an optimization algorithm that gathers information from map routing services and linear solvers. In order to reduce latency and unnecessary computations to a minimum I decided to add a transparent in-memory cache.
The code of the in-memory cache is available as a Gist for now. I plan to put it into a proper repository later. It’s a single file with less than 200 lines of code (including comments). Built upon ConcurrentDictionary, which is suitable for highly concurrent applications.
Design Goals
Avoid duplicate requests: In a traditional cache setting, an algorithm (T1, see diagram below) that wants to fetch a value would first check the cache. If it’s a cache miss, it would request the value from the webservice, wait for the answer to arrive and store the value in the cache. After that any later access (T2) would result in a cache hit.
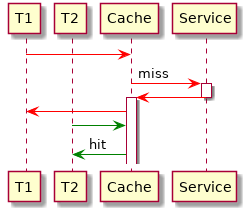
However, in a multithreaded or asynchronous environment there is a major drawback in this concept: If multiple threads (T1, T2, T3) want to fetch the same uncached value, multiple identical requests are sent to the webservice. For example, this situation is common in optimization algoritms where you use some sort of local search heuristic: Many solutions are generated that differ only in a few parts. To evaluate them you need mostly the same values over and over.
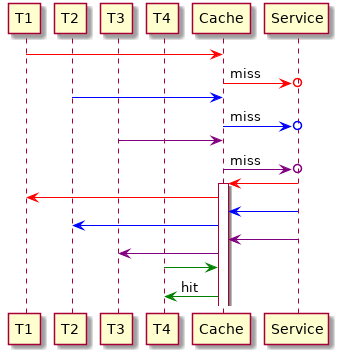
It would be better if all threads would just wait for a single request to avoid unnecessary communication. Effectively this means that we also need to cache pending requests:
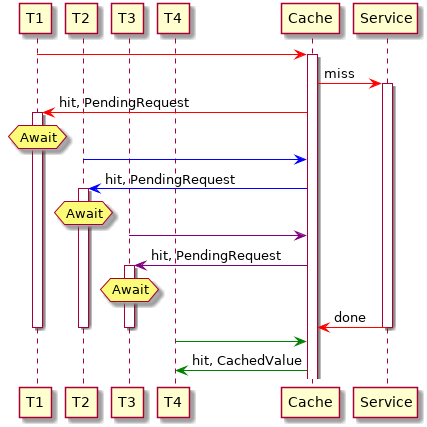
Do not consider stale entries: Cache entries should not be used when they get over a certain age.
Do not cache errors: We only want to cache values and pending requests. No errors, because we don’t want to end up with a negative cache. If a pending request yields an error, all waiting consumers are notified and the pending request is evicted from the cache.
Limited number of entries: The cache should only store a limited amount of entries. To satisfy this limit, entries are evicted from the cache in least recently used (LRU) order before adding new entries.
Non-functional requirements: The algorithm should have a low memory and read overhead as well as being easy to read and maintain.
Alternative Implementations
Here are some alternatives I’ve found in a quick search:
- Based on MemoryCache: https://tech.mikkohaapanen.com/net-c-cache-class-for-caching-task-objects/
- Also based on MemoryCache https://www.hanselman.com/blog/EyesWideOpenCorrectCachingIsAlwaysHard.aspx
- Based on ConcurrentDictionary, but does not prevent duplicate requests https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/how-to-create-pre-computed-tasks
Data Structure
I started with the data structures holding the values. A CacheEntry is a discriminated union of either
- a
CachedValuerecord containing the value itself, last access time and retrieval time or - a
PendingRequestof typeTask.
|
|
The additional values in CachedValue mean:
RetrievedAt: Used to determine if the entry is out-of-date (invalid).LastAccessedAt: Used to sort entries to evict from the cache in LRU order.
Cache Logic
The cache is implemented as a class and holds a reference to a ConcurrentDictionary. request is the function we want to cache. The other parameters maxCount, removeBulkSize, maxRetrievalAge are discussed in the following section.
|
|
The cache can be used like this:
|
|
Lock-free cache read
Any consumer of this cache will call the Get member function in the following code section. If the cache hit a valid value or a pending request, return it via accessValue. If the cache missed (invalid or missing cache entry) we go into getOrRequest. Note how accessValue either waits for the task to yield a result if it’s a PendingRequest or updates the LastAccessedAt time if it’s a CachedValue.
I’m still amazed how concise and readable F# allows us to express this.
|
|
On cache miss
Cache read was the easy part. Now it gets messy because of this property of ConcurrentDictionary described in the Docs:
For modifications and write operations to the dictionary, ConcurrentDictionary<TKey,TValue> uses fine-grained locking to ensure thread safety. (Read operations on the dictionary are performed in a lock-free manner.) However, delegates for these methods are called outside the locks to avoid the problems that can arise from executing unknown code under a lock. Therefore, the code executed by these delegates is not subject to the atomicity of the operation.
In order to guarantee that nobody else has started a request in the meantime, we need to ensure atomicity ourselves. That’s why I added a write lock. In getOrRequest we acquire the lock, make sure the value is still missing and then start the fetch operation with startRequestTask. Note that we hold the lock only for a very brief period of time between reading the cache and creating the PendingRequest.
Within the Task created by startRequestTask we finally call request, put the result in a CachedValue and store it in the cache (which will replace the existing PendingRequest there).
If there is an exception during the request, the PendingRequest is removed and anyone that waits on this task (remember accessValue from above?) gets that exception. Neat.
|
|
If you want to get more functional, startRequestTask would be a good place to extend the code to react to Result.Ok and Result.Error when doing railway oriented programming
The last function havingLockEnsureBound removes excess cache elements.
First it evicts CachedValues in LRU order and if that doesn’t suffice it starts to evict PendingRequests.
This is computationally expensive because we’re sorting all cache elements by access time.
To make this a seldom used operation, we remove a few extra elements (removeBulkSize) as well.
Before optimizing this further, I need to run some performance experiments.
Note that any consumer that still holds a reference to Task will get the result. It just won’t be cached.
|
|